Петля в EVPN-VXLAN. Часть 2. Практика.

Как и обещал, продолжение истории с петлей. Для тех кто не в курсе, первая часть вот тут - https://likeabus.ru/manualstory/2024/09/17/vxlan-loop-1.html.
Собственно, как вы уже поняли, петля всё-таки случилась. Заранее предвещая вопросы. Влияния какого-то не было, т.к. это случилось не в продуктивной среде.
Но давайте пойдём сначала.
Итак, как мы поняли что у нас проблема? Всё очень просто. В какой-то момент логи на коробке прислали сообщение, что CPU приближается к 100%.
CPU H-Ma 09-02-2024 09:10:10 98.19%(Cpu Core)
Ок, но почему петля то сразу? Вдруг там какая-то другая проблема?
Заходим на лиф и смотрим остальные логи:
- Дропы от работы storm-control
HSL : NOTIF : [IF_STORM_DISCARDS_4]: Storm control discards started on interface xX total discards 14938165044
HSL : NOTIF : [IF_STORM_DISCARDS_4]: Storm control discards started on interface xY total discards 45256185512
- Огромное количество разных сообщений по изменению состояния таблиц в BGP и сервисов NSM и HSL.
NSM - network service module, один из ключевых сервисов на уровне Control Plane, занимающийся взаимодействием с Data Plane
HSL - hardware service layer, аналог NSM, но на уровне Data Plane, занимающийся программированием ASICа.
Все логи приводить не буду, иначе будет нечитабельно, но по ходу повествования добавлю ключевые
Аналогичная картина на соседнем лифе в паре.
То есть мы видим следующее: дискарды + флапы MAC адресов и как следствие, всех причастных процессов.
Как видите, уже в принципе понятно, что у нас петля. Но нужно ещё найти место где она возникает и разорвать её.
Ок, петля есть.
Давайте найдём, устраним и только потом будем выяснять причину.
Причем именно в таком порядке :)
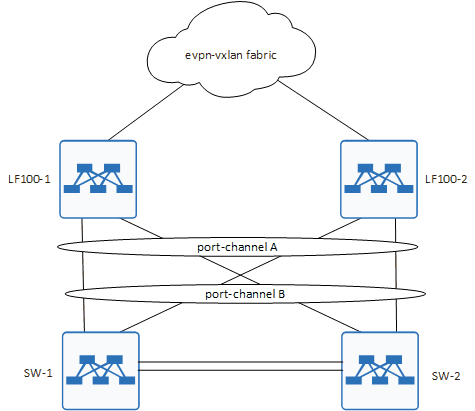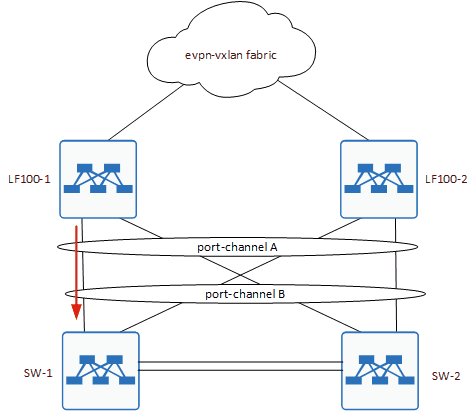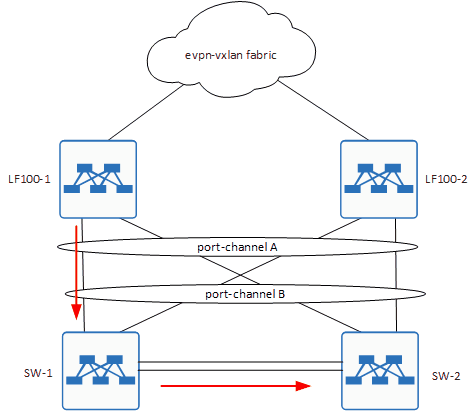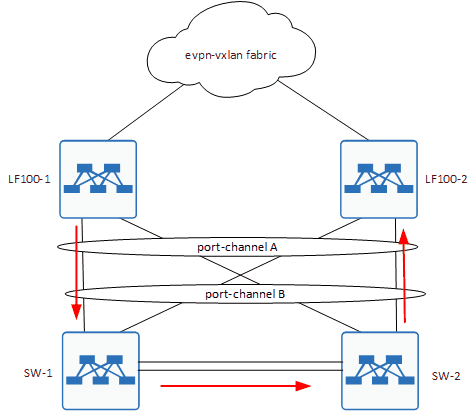
Чтобы увидеть проблему наглядно, нужно обратиться к схеме подключения.
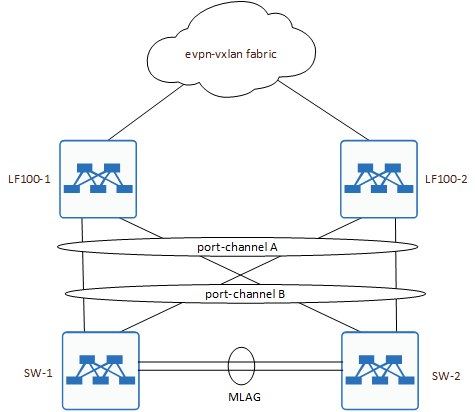
Как видите, она была совсем нетривиальная.
Есть у заказчика такое требование, чтобы к лифам подключались коммутаторы в разных конфигурациях. Это далеко не единственный вариант, в целом мы заранее прорабатываем несколько сценариев возможных подключений хостов и тестируем их. Естественно всё это собирается и проверяется сначала на стенде, только потом уже уезжая на площадку. Тут не исключение.
Не буду ходить вокруг да около. Петлю нашли практически сразу.
Посмотрели конфиги на SW-1/2 и обнаружили, что у нас не настроен MLAG между ними.
То есть получилась вот такая история:
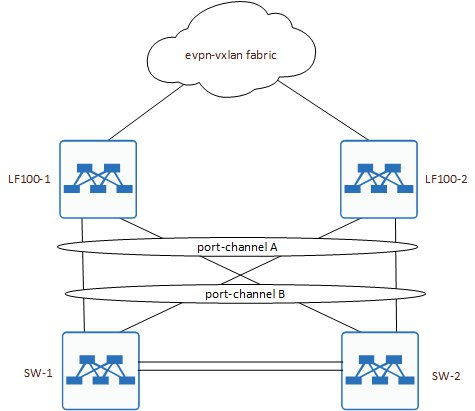
Как видите, у нас была пара общих LAG между всеми коробками. Плюс линк между SW-1 и SW-2. MLAG при этом не был настроен и по факту, это и явилось причиной возникновения петли.
Т.е линк между SW-1 и SW-2, был просто настроен по умолчанию, и т.к. это Huawei, то в отличии от Cisco, у них дефолт - это L2 с включенным MSTP + VLAN 1. Хорошо, разобрались где петля возникала. Достаточно было выключить линки между SW или собрать на них MLAG.
Ок. Шторм обнаружен и устранен.
Но это только часть задачи.
Как инженеру, мне важно учитывать подобные варианты и причины их возникновения, для того, чтобы учесть в будущем и найти способ защиты.
Про влажные мечты и разговоры в духе отказаться полностью от L2 и перейти целиком на L3, никогда не ошибаться в конфигурациях и коммутациях, любить маму и пить компот - в курсе, большое спасибо. Увы (или наоборот к счастью), жизнь чуть сложнее и ставит свои условия.
Например, могу предложить вам решить задачу бесшовной миграции VM между хостами внутри vSphere без общего L2 и опираясь только на L3.
Ну да, забыл, что VMware ушла из РФ и задачи такой больше нет. Ага, ок.
В общем, предлагаю идти дальше в исследовании возникновения проблемы и выявить root cause, после чего попытаться защититься от возникновения подобного шторма.
Собственно тут и начинается самая интересная на мой взгляд часть.
Let`s go deeper.
Как писал ранее, мы делали и storm-control и LAG, плюс есть стандартные механизмы описанные в RFC, которые тоже должны были помочь. Но не помогли. Ниже поясню что к чему.
C LAG всё понятно, нет MLAG, нет и полноценной агрегации. Максимум получим линки поднятые только до одного SW-1 или SW-2.
То есть, либо так:
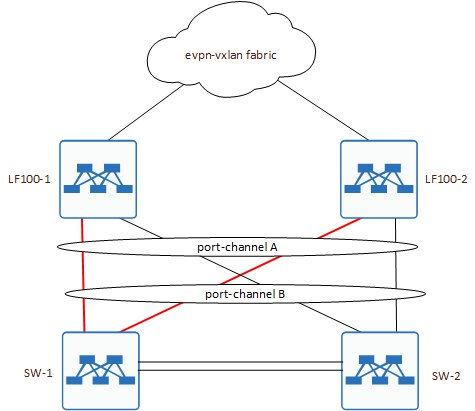
Либо вот так:
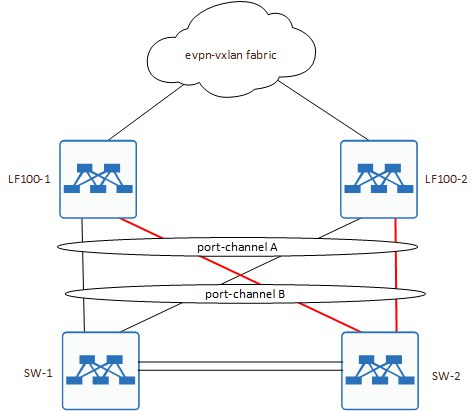
По сути, определится это тем, чей System-ID будет выбран на стороне LF100-1 и LF100-2.
Но не тут-то было.
По факту получилась вот такая схема:
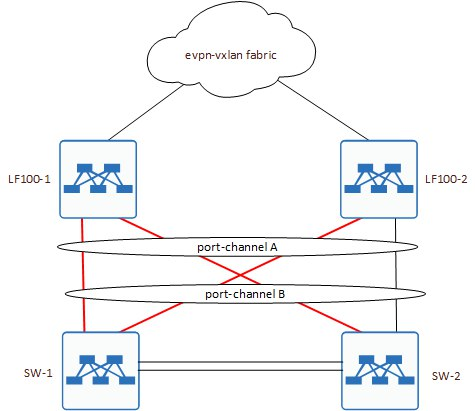
Как вы можете заметить, ВСЕ линки в сторону LF100-1 в UP. Даже от SW-2.
Интересно, да? Почему port-channel с LF100-1 всё-таки активен до обоих узлов?
Причина кроется тоже в конфигурации. Причем тут уже нет ошибок, так и планировалось.
Мы настраивает такую штуку как “lacp force-up”, эта команда превентивно поднимает линки в LAG, не дожидаясь получения LACP BPDU.
Удобно для автоматической настройки линуксовых хостов. Детально можно почитать вот тут:
https://support.huawei.com/enterprise/en/doc/EDOC1100137933/54c5f31b/link-aggregation-commands#EN-US_CLIREF_0141121183При этом на LF100-2 мы такую настройку не делаем, ровно для того, чтобы избежать петли, т.к. LAG собирается только на одной стороне. Схема рабочая и отлично себя показывает для автоматической настройки линуксовых хостов.
Так-так-так. Отлично. Уже вроде становится чуть более понятно, но ещё далеко не всё. Сейчас вы поймёте почему.
В нашей инсталляции всего было 2 хоста:
Первый - жил на SW-1, второй - на SW-2. И оба в одном L2 домене.
Получается, петля возникла между этими двумя? Да, могла.
В дальнейшем, на всех схемах заблокированный линк между LF100-2 и SW-2 убрал, он только будет путать и мешаться.
Вот вам гифка для наглядности:
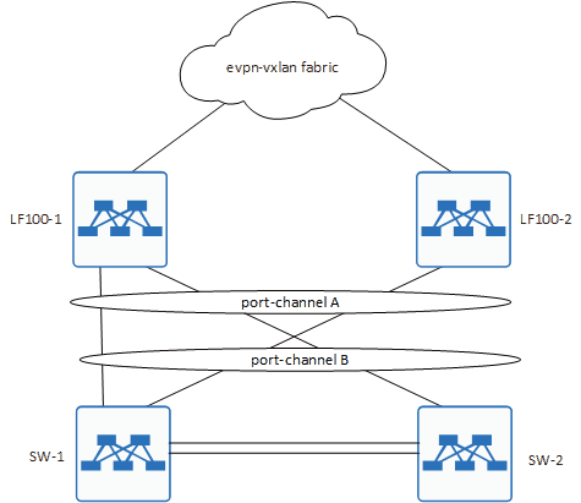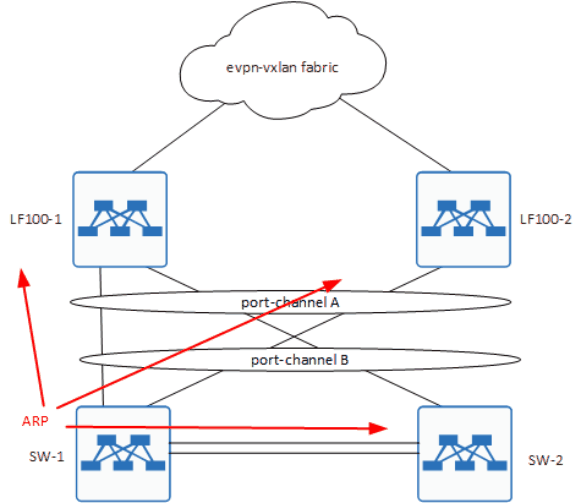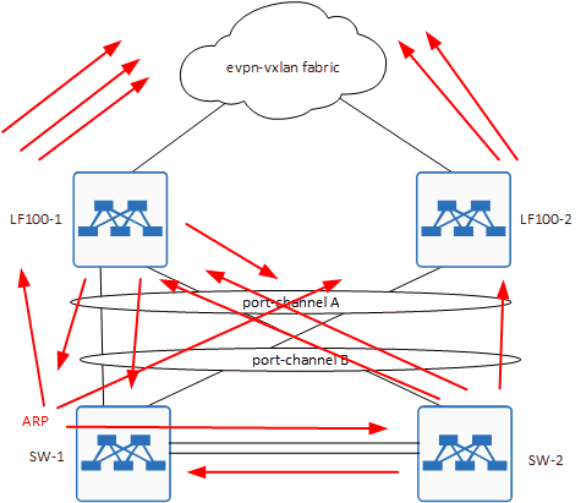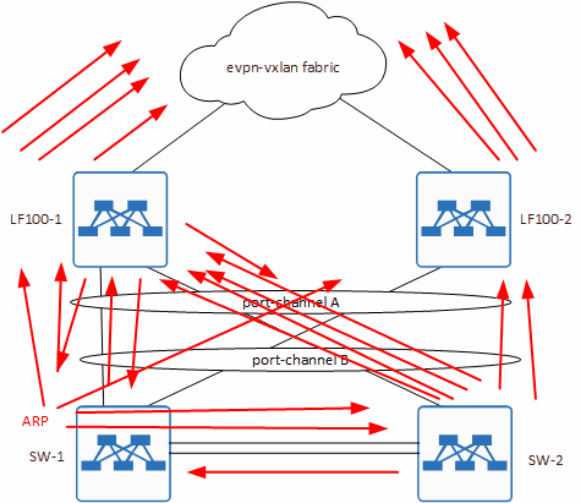
Стрелка - это ARP. По факту, тут показан трафик только со стороны SW-1 и то, как петля возникает с него, но у нас есть хост и на SW-2, который провоцирует ровно тоже самое, но в обратную сторону.
Можно заметить, что единственный, кто хоть как-то старается, это LF100-2, который обратно в сторону хостов BUM трафик не отправляет, т.к. DF - это LF100-1
Так, ну хорошо. Петлю с хостами зафиксировали.
Как мы видели выше в логах, storm-control работает. Лишний трафик действительно отбрасывается.
Есть некий best practice, который не мной был придуман, но уже давно зарекомендовал себя как хорошее значение - 0.1% от ёмкости интерфейса, то есть, если интерфейс 100 Gbps, то при превышении 100 Mbps, всё что больше будет отброшено, для 10G - порог соответственно, находится на 10 Mbps.
Что же насчет флапов MAC адресов? Они ведь тоже у нас бесконечно идут, и MAC выучивается то с одной стороны, то с другой.
В EVPN у нас есть такая штука как MAC Mobility, которая использует extended community с указанием в нём sequence, что и позволяет плавно переводить трафик с одного лифа на другой, для конкретного MAC адреса. То есть, если у вы делаете первый анонс внутрь фабрики, то ставите sequence равный 0, и все его получают. Если же, кто-то хочет сделать новый анонс для точно такого же маршрута, то он уже знает о существовании маршрута с sequence равным нулю и добавляет к своему анонсу +1. Таким образом все получают новый update, где sequence выше текущего и переводят трафик в сторону этого лифа.
Если что, это и есть ответ на задачу по бесшовной миграции для vSphere Как вы могли заметить выше, во время возникновения петли, трафик с хостов уходил то в одну сторону, то в другую. Получается лифы были вынуждены его поочередно анонсировать с sequence +1.
Так. Выходит EVPN не учитывает такой сценарий?
Нет, учитывает.
Если коротко, то за определенный промежуток времени sequence вырастает до значения равного 6, это расценивается как mac flooding и дальше повышение выключается, плюс MAC фиксируется. Происходит так называется MAC freezing
Cобственно вот тут он описан - https://datatracker.ietf.org/doc/html/rfc7432#section-15.1
Идём смотреть логи.
LF100-1 : NSM : NOTIF : [EVPN_MAC_MOBILITY_4]: Max Host movement VPN-ID 123: MAC MAC_HOST_1 and IP IP_HOST_1 moved to conflict state, resolve manually.This MAC also moved to discard till 300 seconds
LF100-1 : NSM : NOTIF : [VXLAN_OPR_MAC_IP_MOVE_IGNORED_4]: Max host movement VPN-ID 123: MAC MAC_HOST_1 mobility ignored because of CONFLICT
Признаться, когда я нашёл этот лог, то был не просто рад, а пиздец как рад. (с)
Ну что, выходит всё? Петля нашлась, storm-control работал. MAC Mobility тоже нас выручил и заблокировал флаппинг внутри BGP. Откуда же CPU 100% на протяжении длительного времени? Ведь всё, что я описал выше - это секунды.
Тут мы подходим к финальной части повествования.
FINISH HIM !!
Есть такой механизм, называется он ARP-ND-REFRESH. Удобная штука для silent хостов, которые молчат и только отвечают, если видят направленный ARP или ND.
Работает по следующему сценарию.
- Лиф отправляет ARP-REQUEST и ND в сторону хоста со своим anycast gateway MAC в качестве source.
- Хост получает ARP и выучивает адрес лифа, а в ответ отправляет ARP-REPLY.
- Лиф обновляет таблицу ARPов, плюс если это требуется, отдаёт новый TYPE-2 в сторону EVPN облака.
- Профит.
Но что будет, если у нас петля?
А будет то, что запетляется ещё и вот этот наш ARP, который ушёл с лифа.
Покажу как это происходит на примере одного пакета, сам шторм показывать не буду, он аналогичен тому, что выше.
Как видите, наш собственный ARP, попадает к нам изнутри. То есть со стороны хостов. И тут происходит ровно то, что приводит к загрузке CPU до 100%.
LF100-1 : HSL : INFO : [NVO_OPR_HW_INFO_5]: VPN-ID 123: MAC removed in mac hash MAC aaaa.bbbb.cccc
LF100-1 : NSM : NOTIF : [EVPN_MAC_MOBILITY_4]: VPN-ID 123: MAC aaaa.bbbb.cccc update Static Local to Dynamic Local on irb123 outer-vlan 0, inner-vlan 0 dynamically learnt on po1 outer-vlan 0, inner-vlan 0
Ключевое сообщение - Static Local to Dynamic Local.
Таких сообщений, в логах несколько тысяч. То есть т.к. MAC есть локально, но мы получаем его из вне, происходит бесконечный MAC learning, который и кладёт нам процессор.
В итоге, если выключить ARP-ND-REFRESH, то мы уберём отправку ARP-REQUEST с лифов и больше такого не произойдёт.
Всё. Вот теперь точно конец.
Не забывайте поделиться с коллегами, друзьями и тем, кто по вашему мнению будет заинтересован. Таким образом вы окажете поддержку мне и выразите свою благодарность.
Спасибо за внимание!